
Part 1
I. What is Full-text search?
In short, Full-text search is the most natural way to search for information. It likes when you google a term, you only need to type a keyword in search box and press 'Enter' and then the results will appear. In the scope of this entry, we only discuss about Full-text search in MySQL but don't discuss about other Full-text search engines such as Sphinx or Solr.
II. Why we need to use Full text search?
In common case, you can use this query for searching an keyword in MySQL:
SELECT id,title,description FROM book WHERE title LIKE ‘%keyword%’
However, this approach has several limitation such as:
(Note: These limitations in MySQL query, even if in MySQL Full-text search does not solve completely these issues. We have to use other search engines such as Sphinx, Solr etc. But I want to mention in this entry to have a clear understanding about these disadvantages)
1. Inaccuracy
- Noise words
Supposing that we have a query with a LIKE clause as below:
Title LIKE ‘%one%’
MySQL will returns several possible results likes: one, zone, money, phone. Basically, these results are not accuracy and contain unexpected results.
- Synonyms
Any language has synonyms, for example in English, we have different words that have the same meaning such as: color-colour, check-cheque, taxi-cab, beautiful-pretty, intelligent-smart etc. If we only use LIKE clause, we cannot solve this problem (even if with MySQL Full-text search, it is still a big obstacle).
- Acronym
Sometimes with the long common phrase, we usually use acronyms instead of the whole phrases such as SaaS, OOP, LA, EU etc. However, users do not always search in only one way. They can search for a term either in long form or short form in a unforeseen way. From a user perspective, they want to get their expected results whether which form they put in the search box.
2. Slow query performance, ‘%keyword%’ does not use index
If we use wildcard characters such as "%" in a query, MySQL will perform that query without using index. It will scan through the whole data from begin to the end, therefore it is very slow compare to search on index. It likes we find a certain sentence in a book by looking page by page rather than using index in behind of the book. In order to understand why using index is faster, we will discuss it in later part of this series.
The index also can be used for LIKE comparisons if the argument to LIKE is a constant string that does not start with a wildcard character[1]

3. Problem with languages that have diacritic or accent mark
Supposing we search for a Vietnamese phrase in database. With the LIKE clause, we can not find the row we need, when user put the search phrase without the accent marks. There is a solution for this problem by using 2 fields in database. One for data with diacritical marks and one for data without diacritical marks. However, it is still not complete solution, because it cannot find approximately match results. For example, if users perform a search that looking for the phrase "co be mua dogn" in database. If we only use LIKE clause, it cannot return relevance results "Cô bé mùa đông" for us. However, Full-text search can solve this problem.
III. MySQL full text search at a glance.
In short, MySQL Full-text search is available for MyISAM storage engine, and for InnoDB above MySQL 5.6
There are 2 search mode including BOOLEAN MODE and NATURAL LANGUAGE MODE. In BOOLEAN MODE, there is no default sorting, and in this mode we can indicate which words will appear in the results and which words does not. In NATURAL LANGUAGE MODE, the results are return based on the similarity between the keywords and the text in database. The similarities between the query and the text are based on the weight of keywords in database (the calculation is described here).
By default, MySQL has a list of stopwords. In other words, MySQL will ignores these words in the query (e.g: the, and, or, for etc.). The full list of stopwords can be found on MySQL website here.
Moreover, MySQL only search for a word that has minimum 4 characters long (global variable ft_min_word_len =4). It is a very common question, why MySQL cannot find phrase that only contain short words such as "The way I am", "To be or not to be" etc. Therefore, we have to keep in mind this default variable value.
SHOW VARIABLES LIKE 'ft%'

{kind=link}
IV. Sample application
CREATE TABLE IF NOT EXISTS `jobs` ( `id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT, `id_user` INT(11) UNSIGNED DEFAULT NULL, `title` VARCHAR(255) COLLATE utf8_unicode_ci NOT NULL, `location` VARCHAR(255) COLLATE utf8_unicode_ci NOT NULL, `description` TEXT COLLATE utf8_unicode_ci NOT NULL, FULLTEXT INDEX(title, description), ) ENGINE=MyISAM COLLATE=utf8_unicode_ci; SELECT * FROM `jobs ` WHERE MATCH(title, description) AGAINST (‘developers’ IN NATURAL LANGUAGE MODE); SELECT * FROM `jobs ` WHERE MATCH(title, description) AGAINST (‘developers’ IN BOOLEAN MODE);In this entry, we only take a quick glance at MySQL Full-text search. In the next part, we will learn more about its syntax, NATURAL LANGUAGE MODE and BOOLEAN MODE.
Part 2
In this part, we discuss deeper about MySQL Full-Text syntax and how to use it in MySQL. We will use this database schema for the further example in this part and later part.CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
);
INSERT INTO articles (title,body)
VALUES('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
NATURAL LANGUAGE MODE and BOOLEAN MODE
MATCH (col1,col2,...) AGAINST (expr [search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
In Natural Language Mode [1], MySQL looks for concepts rather than exact words based on the "free-text queries" that we input, MATCH…AGAINST returns ranking score based on the relevance between the keyword and the document (the similarities between keywords and documents). The more similarity the have, the higher rank the document has. In order to know the rank of a document against the keywords, we can perform this query below:
SELECT id, ROUND(MATCH(title, body) AGAINST('database'), 7) FROM `articles`

In Boolean Mode [2], searches are performed based on exactly the words that we gave them, and the results are not sorted in any order. It is different to Natural Language Mode, we can even do searches without Full-text Index. Moreover, we can use some operators such as + and - to modify the query and determine the final results (which words are available in the result and which words are not).
For example:
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);
The results of the query above only returns the documents which contains the word "MySQL" but doesn't return documents which contains the word "YourSQL". Moreover, we can use wildcard characters to modify the ranking of results entry based on our will.
Example:
Find rows that contain at least one of the two words.
2. ‘+apple +juice’
Find rows that contain both words.
3. ‘+apple macintosh’
Find rows that contain the word “apple”, but rank rows higher if they also contain “macintosh”.
4. ‘+apple –macintosh’
lFind rows that contain the word “apple” but not “macintosh”.
5. ‘+apple ~macintosh’
Find rows that contain the word “apple”, but if the row also contains the word “macintosh”, rate it lower than if row does not. This is “softer” than a search for '+apple -macintosh', for which the presence of “macintosh” causes the row not to be returned at all.
6. ‘+apple +(>turnover <studel)
Find rows that contain the words “apple” and “turnover”, or “apple” and “strudel” (in any order), but rank “apple turnover” higher than “apple strudel”.
7. ‘apple*‘
Find rows that contain words such as “apple”, “apples”, “applesauce”, or “applet”.
8. ‘”some words“’
Find rows that contain the exact phrase “some words” (for example, rows that contain “some words of wisdom” but not “some noise words”).
With Query Expansion (WITH QUERY EXPANSION or IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION), MySQL will perform the search two times. In the second times, MySQL will combine the original keywords with some highlighted words in the first results.
Example:
We look for the term "database" and MySQL returns the results as below: (based on the above data):
SELECT * FROM articles WHERE MATCH(title,body) AGAINST('database');

With Query Expansion, MySQL recognizes that in the two result rows, they both contain the common word "MySQL". Therefore, MySQL also perform the search with the keyword "MySQL". Although they are not contain the word "database".

According to MySQL document, the searches with Query Expansion modifier can increase the noise and non-relevance results. Therefore we should only use it with short keywords.
We should use Boolean Mode when the number of rows in database is too small, or with the repeated testing data. Because the mechanism of Natural Language Mode ranks the words based on the frequencies of those words in the collection. The more it appears in the collection (row, table), the lower its score. Therefore the possibility that MySQL returns the empty set is very high.
There is a small issue with Boolean Mode. When we search for keywords that contains some special characters such as (+-,~,<,* etc), those keywords are reversed wildcard characters in Boolean Mode. For example, the term "SBD-1107" contains the character "-" (hyphen or dash), and it is duplicate with the "-" operator in Boolean Mode. In this case, we can use addition phrase "HAVING field LIKE 'SBD-1107%'" to search. As described in former part, the LIKE operator with the "%" in the end still use index for searching. Therefore it is still fast.
Part 3
In this part, we dicuss about relevance of a document for a keyword and the indexing mechanism of MySQL.1. Overall architecture
Firstly, we should take a look at the overall architecture of Full-text search engine including MySQL. However, it depends on each search engine. For example, MySQL does not have stemmer, therefore it distinguish between plural and single nouns.

In the first processing, tokenizer will hash the input document into smallest document units. It really depends on the input language. For example, English and Vietnamese the smallest unit is word, but to Chinese, Japanese, Korean it is character). Technically, words are separated by white spaces, but to CJK languages, words and characters possibly don't have any separator.
Then with the stemming process, stemmer have to reduce the derived words to their stem, base or root form. For example, in English, jump, jumps, jumped, jumping all have the same root "jump".
Afterward, the input document will be filtered out stopwords. In other words, removing words that don't have any meanings to the ranking process. For example, by default to MySQL, words such as hello, welcome, were, it, us etc. will be removed from index (see the full stopword list here).
2. What is Index?
Based on Wikipedia, Index is a sort of data structure that improve the accessing speed of data. However, it increases the writing time and cost more storage space. In fact, you can see index structure in real life, behind books. They are the list of words and related page that helps readers easily look up for a word present in which page of that book. We can take a look at index of the book "Lucence in Action".

The common index structure in search engines is Inverted Index.
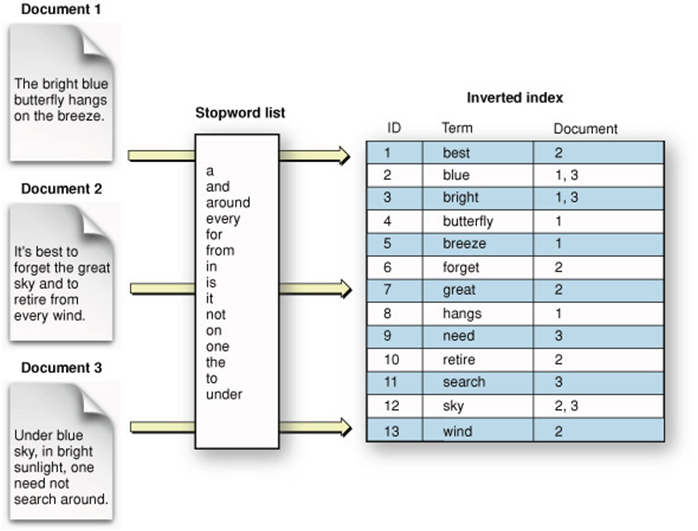
3. Relevance Rank
As mentioned in part 2, by default, Natural Language Mode is sort by relevance. The relevance score is called "weight", and it is calculated by this formula:
w = (log(dtf)+1)/sumdtf * U/(1+0.0115*U) * log((N-nf)/nf)
Particularly, we can read more about the algorithm in this article MySQL Internal Algorithm. However, we can simply understand this algorithm by the following explain:
If a keyword appears many times in a document, then the weight of its keyword is increased. But if the keyword appears in many other documents, then its weight is decreased.
Thus, a word does not appear in any document and the word appear in all document all have low weight and harder to find. For example, the keyword "MySQL" in the previous part.
In order to understand more about the ranking, we can look the the weight that MySQL calculated for each indexed word. We can use the tool mysql_ftdump in mysql\bin (the parameter -c means count and 1 is the Full-text index(title, body) and 0 is index of id)

{kind=link}
As we can see, the keyword MySQL can be negative (less than 0). Because the the keyword appears in all rows in the table that we use for testing. If we try another keyword, at least one result will be returned. Note: by default the query is perform in Natural Language Mode, but if we change to Boolean Mode, results are still returned. Because in Boolean Mode, the engine only search for the existence of the keyword (1 or 0).
Here will will come back with the Boolean Mode to understand the weight in this mode.

{kind=link}
As depicted in the figure, the weights are only 1 or 0, they describe the existence of a keyword in collection. However, the weight will be higher or lower if we use wildcard character as mentioned in the part 2.
Take a look at these 2 example:

The score of 5th record is less than 1, because it contains the word "YourSQL" (the wildcard character ~ mark it as a noise word, therefore it has lower weight).
In contrast, if we add leading < operator, the weight of 5th record is increased.

Because of the < operator before YourSQL, so that the 5th record's weight is higher than usual. Therefore when we use wildcards, the weight in Boolean Mode is not binary value any more. As a result, we have to sort the results in order to retrieve the expected result by using ORDER BY MATCH...AGAINST...
4. Fine-tuning
As mentioned above, we should notice that by default MySQL only index word that has minimum 4 characters in length.
For example, terms such as "This is me", "The way I am", "Let her go" (some song titles) cannot be found even though the total length of these terms are greater than 4, but individually each word is shorter than 4 characters. If we search for the term "PHP devlopers", the word PHP will be skipped because it only has 3 chars.
In order to search for words which has length shorter than 4 chars, we have to configure MySQL (in my.ini or my.cnf) the ft_min_word_len = 3 ( or lower 3, if we want to search CJK language, we have to set this variable = 1).
Moreover, by default MySQL has a build-in stopword list, if we don't want to use it, we can re-config the variable ft_stop_word_file='path/to/your/file.txt'. The file contains the word that we want to filter out from the input. Each word are separated by a carriage return character (new line).
For the configurations take effects, we have to restart MySQL and rebuild the index by the command bellow:
REPAIR TABLE table_name QUICK;

Hung Nguyen
No comments:
Post a Comment